कुबेरनेट्स पर PySpark माइक्रोसर्विस की तैनाती: इलम के साथ डेटा झीलों में क्रांति लाना।

अभिवादन इलम उत्साही और पायथन प्रशंसकों! हम एक नई, उत्सुकता से अपेक्षित सुविधा का अनावरण करने के लिए रोमांचित हैं जो आपकी डेटा विज्ञान यात्रा को सशक्त बनाने के लिए तैयार है - इलम में पूर्ण पायथन समर्थन। डेटा की दुनिया में उन लोगों के लिए, पायथन और अपाचे स्पार्क लंबे समय से एक प्रतिष्ठित जोड़ी रही है, जो डेटा और जटिल गणनाओं के विशाल संस्करणों को मूल रूप से संभालती है। और अब, इलम के नवीनतम अपग्रेड के साथ, आप अपने पसंदीदा डेटा लेक वातावरण के अंदर पायथन की शक्ति का उपयोग कर सकते हैं।
यह ब्लॉग पोस्ट इस सुविधा की खोज के लिए आपका निर्देशित दौरा है। हम पायथन में लिखे गए एक साधारण अपाचे स्पार्क जॉब के साथ चीजों को बंद कर देंगे, इसे इलम पर चलाएं, और फिर गहराई से गोता लगाएँ। हम एक इंटरैक्टिव मोड का समर्थन करने के लिए प्रारंभिक कोड को बदल देंगे, जो आपको इलम के एपीआई के माध्यम से स्पार्क नौकरी तक सीधी पहुंच प्रदान करता है। इस यात्रा के अंत तक, आपके पास एपीआई कॉल का जवाब देने वाला एक पायथन-आधारित माइक्रोसर्विस होगा, जो सभी इलम पर सुचारू रूप से चल रहे हैं।
तो, क्या आप पायथन और इलम के साथ अपने डेटा गेम को बढ़ाने के लिए तैयार हैं? आएँ शुरू करें।
सभी उदाहरण हमारे पर उपलब्ध हैं GitHub भंडार .
चरण 1: पायथन में एक साधारण अपाचे स्पार्क जॉब लिखना।
इससे पहले कि हम इलम के साथ अपनी पायथन यात्रा शुरू करें, हमें यह सुनिश्चित करने की आवश्यकता है कि हमारा पर्यावरण अच्छी तरह से सुसज्जित है। स्पार्क जॉब चलाने के लिए, आपको Ilum और PySpark इंस्टॉल करने की आवश्यकता है। आप PySpark सेट करने के लिए pip, Python पैकेज इंस्टॉलर का उपयोग कर सकते हैं। सुनिश्चित करें कि आप पायथन > = 3.9 का उपयोग कर रहे हैं।
पाइप स्थापित Pyspark इलम को स्थापित करने और एक्सेस करने के लिए, कृपया दिए गए दिशानिर्देशों का पालन करें यहाँ .
1.1 स्पार्कपी उदाहरण।
अब, आइए अपनी स्पार्क नौकरी लिखने में गोता लगाएँ। हम SparkPi के एक सरल उदाहरण के साथ शुरू करेंगे
sys आयात करें
यादृच्छिक आयात यादृच्छिक से
ऑपरेटर आयात ऐड से
pyspark.sql आयात से SparkSession
यदि __name__ == "__main__":
स्पार्क = स्पार्कसेशन \
।भवन-निर्माता\
.appName("PythonPi") \
.getOrCreate()
विभाजन = int(sys.argv[1]) if len(sys.argv) > 1 और 2
n = 100000 * विभाजन
def f(_: int) -> फ्लोट:
x = यादृच्छिक () * 2 - 1
y = यादृच्छिक () * 2 - 1
रिटर्न 1 अगर एक्स ** 2 + वाई ** 2 <= 1 और 0
गिनती = spark.sparkContext.parallelize (रेंज (1, एन + 1), विभाजन).मैप (एफ) .कम करें (जोड़ें)
प्रिंट ("पाई लगभग % f"% (4.0 * गिनती / n))
स्पार्क.स्टॉप () इस स्क्रिप्ट को इस रूप में सहेजें ilum_python_simple.py
हमारी स्पार्क नौकरी तैयार होने के साथ, इसे इलम पर चलाने का समय आ गया है। इलम इलम यूआई का उपयोग करके या आरईएसटी एपीआई के माध्यम से नौकरियां जमा करने की क्षमता प्रदान करता है।
आइए UI के साथ शुरू करें एकल नौकरी सुविधा।
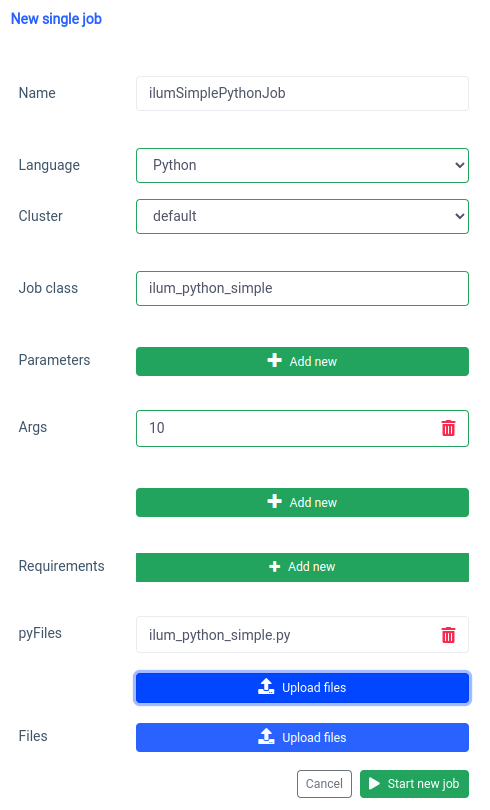
हम एक ही चीज़ के साथ हासिल कर सकते हैं एपीआई , लेकिन पहले, हमें पोर्ट फॉरवर्ड के साथ इलम-कोर एपीआई को उजागर करने की आवश्यकता है।
Kubectl पोर्ट-फॉरवर्ड SVC/ILUM-Core 9888:9888 उजागर पोर्ट के साथ हम एक एपीआई कॉल कर सकते हैं।
कर्ल -एक्स पोस्ट 'लोकलहोस्ट: 9888/एपीआई/वी1/जॉब/सबमिट' \
--फॉर्म 'नाम = "ilumSimplePythonJob"' \
--फॉर्म 'क्लस्टरनाम = "डिफ़ॉल्ट"' \
--फॉर्म 'जॉबक्लास = "ilum_python_simple"' \
--फॉर्म 'args = "10"' \
--फॉर्म 'pyFiles=@"/path/to/ilum_python_simple.py"' \
--form 'language="PYTHON"' API कॉल
नतीजतन, हमें बनाई गई नौकरी की आईडी प्राप्त होगी।
{"jobId":"20230724-1154-m78f3gmlo5j"} परिणाम
नौकरी के लॉग की जांच करने के लिए हम एपीआई कॉल कर सकते हैं
कर्ल लोकलहोस्ट:9888/API/v1/job/20230724-1154-m78f3gmlo5j/logs API कॉल
और बस! आपने इलम पर एक साधारण पायथन स्पार्क नौकरी लिखी और चलाई है। आइए थोड़ा और उन्नत उदाहरण देखें जिसके लिए अतिरिक्त पायथन पुस्तकालयों की आवश्यकता है।
1.2 सुन्न के साथ नौकरी का उदाहरण।
इस खंड में, हम पायथन में लिखे गए स्पार्क जॉब के व्यावहारिक उदाहरण पर जाएंगे। इस नौकरी में डेटासेट पढ़ना, उसे संसाधित करना, उस पर मशीन लर्निंग मॉडल का प्रशिक्षण देना और भविष्यवाणियों को सहेजना शामिल है। हम एक का उपयोग करने जा रहे हैं Tel-churn.csv फ़ाइल, जिसे आप हमारे GitHub भंडार . चीजों को आसान बनाने के लिए, हमने इस फ़ाइल को MinIO के बिल्ड-इन इंस्टेंस में ilum-files नामक बाल्टी में अपलोड किया है, जो Ilum इंस्टेंस से स्वचालित रूप से सुलभ है। इसका मतलब है कि आपको इस उदाहरण के लिए किसी भी एक्सेस को कॉन्फ़िगर करने के बारे में चिंता करने की ज़रूरत नहीं होगी - इलम ने इसे कवर किया है। हालाँकि, यदि आप कभी भी किसी भिन्न बाल्टी से डेटा प्राप्त करना चाहते हैं या अपनी परियोजनाओं में अमेज़ॅन एस 3 का उपयोग करना चाहते हैं, तो आपको तदनुसार एक्सेस को कॉन्फ़िगर करना होगा।
अब जब हमने अपना डेटा तैयार कर लिया है, तो आइए पायथन में अपना स्पार्क जॉब लिखना शुरू करें। यहाँ पूर्ण कोड उदाहरण है:
pyspark.sql आयात से SparkSession
pyspark.ml आयात पाइपलाइन से
pyspark.ml.feature से आयात स्ट्रिंगइंडेक्सर, वेक्टरअसेंबलर
pyspark.ml.classification से आयात LogisticRegression
यदि __name__ == "__main__":
स्पार्क = स्पार्कसेशन \
।भवन-निर्माता\
.appName("IlumAdvancedPythonExample") \
.getOrCreate()
df = spark.read.csv('s3a://ilum-files/Tel-churn.csv', header=True, inferSchema=True)
श्रेणीबद्ध कॉलम = ['लिंग', 'साथी', 'आश्रित', 'फोन सेवा', 'मल्टीपललाइन्स', 'इंटरनेट सेवा',
'ऑनलाइन सुरक्षा', 'ऑनलाइन बैकअप', 'डिवाइस प्रोटेक्शन', 'टेकसपोर्ट', 'स्ट्रीमिंगटीवी',
'स्ट्रीमिंगमूवीज', 'कॉन्ट्रैक्ट', 'पेपरलेस बिलिंग', 'पेमेंट मेथड']
चरण = []
categoricalColumns में categoricalCol के लिए:
stringIndexer = StringIndexer (inputCol = categoricalCol, outputCol = categoricalCol + "इंडेक्स")
चरण + = [स्ट्रिंगइंडेक्सर]
label_stringIdx = स्ट्रिंगइंडेक्सर (इनपुटकोल = "मंथन", आउटपुटकोल = "लेबल")
चरण += [label_stringIdx]
संख्यात्मक Cols = ['वरिष्ठ नागरिक', 'कार्यकाल', 'मासिक शुल्क']
assemblerInputs = [c + "सूचकांक" categoricalColumns में c के लिए] + संख्यात्मक Cols
कोडांतरक = वेक्टरअसेंबलर (इनपुटकोल्स = असेंबलरइनपुट, आउटपुटकोल = "फीचर्स")
चरण += [कोडांतरक]
पाइपलाइन = पाइपलाइन (चरण = चरण)
pipelineModel = pipeline.fit(df)
डीएफ = pipelineModel.transform(df)
ट्रेन, परीक्षण = df.randomSplit([0.7, 0.3], बीज = 42)
lr = LogisticRegression (featuresCol = "features", labelCol = "label", maxIter = 10)
lrModel = lr.fit (ट्रेन)
भविष्यवाणियां = lrModel.transform (परीक्षण)
predictions.select("customerID", "लेबल", "भविष्यवाणी").शो(5)
predictions.select("customerID", "लेबल", "भविष्यवाणी").write.option("हेडर", "सच") \
.csv('s3a://ilum-files/predictions')
स्पार्क.स्टॉप () आइए कोड में गोता लगाएँ:
pyspark.sql आयात से SparkSession
pyspark.ml आयात पाइपलाइन से
pyspark.ml.feature से आयात स्ट्रिंगइंडेक्सर, वेक्टरअसेंबलर
pyspark.ml.classification से आयात LogisticRegression यहां, हम स्पार्क सत्र बनाने, मशीन लर्निंग पाइपलाइन बनाने, डेटा को प्रीप्रोसेस करने और लॉजिस्टिक रिग्रेशन मॉडल चलाने के लिए आवश्यक PySpark मॉड्यूल आयात कर रहे हैं।
स्पार्क = स्पार्कसेशन \
।भवन-निर्माता\
.appName("IlumAdvancedPythonExample") \
.getOrCreate() हम एक स्पार्कसेशन , जो स्पार्क में किसी भी कार्यक्षमता का प्रवेश बिंदु है। यह वह जगह है जहां हम एप्लिकेशन नाम सेट करते हैं जो स्पार्क वेब यूआई पर दिखाई देगा।
df = spark.read.csv('s3a://ilum-files/Tel-churn.csv', header=True, inferSchema=True) हम एक मिनीओ बाल्टी पर संग्रहीत एक सीएसवी फ़ाइल पढ़ रहे हैं। वही हेडर = सच विकल्प स्पार्क को हेडर के रूप में CSV फ़ाइल की पहली पंक्ति का उपयोग करने के लिए कहता है, जबकि inferSchema=True स्पार्क स्वचालित रूप से प्रत्येक कॉलम के डेटा प्रकार को निर्धारित करता है।
श्रेणीबद्ध कॉलम = ['लिंग', 'साथी', 'आश्रित', 'फोन सेवा', 'मल्टीपललाइन्स', 'इंटरनेट सेवा',
'ऑनलाइन सुरक्षा', 'ऑनलाइन बैकअप', 'डिवाइस प्रोटेक्शन', 'टेकसपोर्ट', 'स्ट्रीमिंगटीवी',
'स्ट्रीमिंगमूवीज', 'कॉन्ट्रैक्ट', 'पेपरलेस बिलिंग', 'पेमेंट मेथड'] हम अपने डेटा में उन कॉलम को निर्दिष्ट करते हैं जो श्रेणीबद्ध हैं। इन्हें बाद में स्ट्रिंगइंडेक्सर का उपयोग करके रूपांतरित किया जाएगा।
चरण = []
categoricalColumns में categoricalCol के लिए:
stringIndexer = StringIndexer (inputCol = categoricalCol, outputCol = categoricalCol + "इंडेक्स")
चरण + = [स्ट्रिंगइंडेक्सर] यहां, हम श्रेणीबद्ध कॉलम की हमारी सूची पर पुनरावृत्ति कर रहे हैं और प्रत्येक के लिए एक स्ट्रिंगइंडेक्सर बना रहे हैं। स्ट्रिंगइंडेक्सर्स श्रेणीबद्ध स्ट्रिंग कॉलम को सूचकांकों के कॉलम में एन्कोड करते हैं। रूपांतरित अनुक्रमणिका स्तंभ को "अनुक्रमणिका" के साथ जोड़े गए मूल स्तंभ नाम के रूप में नामित किया जाएगा.
संख्यात्मक Cols = ['वरिष्ठ नागरिक', 'कार्यकाल', 'मासिक शुल्क']
assemblerInputs = [c + "सूचकांक" categoricalColumns में c के लिए] + संख्यात्मक Cols
कोडांतरक = वेक्टरअसेंबलर (इनपुटकोल्स = असेंबलरइनपुट, आउटपुटकोल = "फीचर्स")
चरण += [कोडांतरक] यहां हम अपने मशीन लर्निंग मॉडल के लिए डेटा तैयार करते हैं। हम एक VectorAssembler बनाते हैं जो हमारे सभी फीचर कॉलम (श्रेणीबद्ध और संख्यात्मक दोनों) लेगा और उन्हें एक एकल वेक्टर कॉलम में इकट्ठा करेगा। स्पार्क में अधिकांश मशीन लर्निंग एल्गोरिदम के लिए यह एक आवश्यकता है।
ट्रेन, परीक्षण = df.randomSplit([0.7, 0.3], बीज = 42) हम अपने डेटा को एक प्रशिक्षण सेट और एक परीक्षण सेट में विभाजित करते हैं, जिसमें प्रशिक्षण के लिए 70% डेटा और परीक्षण के लिए शेष 30% होता है।
lr = LogisticRegression (featuresCol = "features", labelCol = "label", maxIter = 10)
lrModel = lr.fit (ट्रेन) हम अपने प्रशिक्षण डेटा पर एक लॉजिस्टिक रिग्रेशन मॉडल को प्रशिक्षित करते हैं।
भविष्यवाणियां = lrModel.transform (परीक्षण)
predictions.select("customerID", "लेबल", "भविष्यवाणी").शो(5)
predictions.select("customerID", "लेबल", "भविष्यवाणी").write.option("हेडर", "सच") \
.csv('s3a://ilum-files/predictions') अंत में, हम अपने परीक्षण सेट पर भविष्यवाणियां करने के लिए अपने प्रशिक्षित मॉडल का उपयोग करते हैं, पहले 5 भविष्यवाणियों को प्रदर्शित करते हैं। फिर हम इन भविष्यवाणियों को अपने मिनीओ बाल्टी में वापस लिखते हैं।
इस स्क्रिप्ट को इस रूप में सहेजें ilum_python_advanced.py
pyspark.ml एक निर्भरता के रूप में numpy का उपयोग करता है जो डिफ़ॉल्ट के रूप में स्थापित नहीं है इसलिए हमें इसे आवश्यकता के रूप में निर्दिष्ट करने की आवश्यकता है।
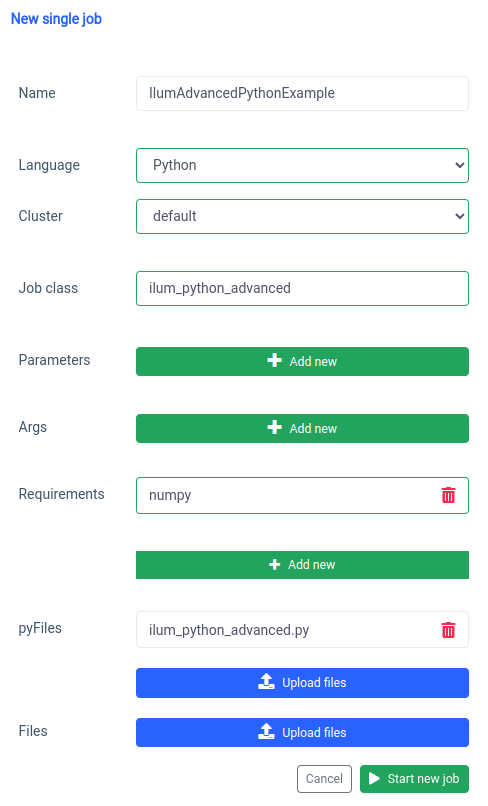
और एपीआई के माध्यम से भी ऐसा ही किया जा सकता है।
कर्ल -एक्स पोस्ट 'लोकलहोस्ट: 9888/एपीआई/वी1/जॉब/सबमिट' \
--फॉर्म 'नाम = "IlumAdvancedPythonExample"' \
--फॉर्म 'क्लस्टरनाम = "डिफ़ॉल्ट"' \
--फॉर्म 'जॉबक्लास = "ilum_python_advanced"' \
--फॉर्म 'pyRequirements = "numpy"' \
--फॉर्म 'pyFiles=@"/path/to/ilum_python_advanced.py"' \
--form 'language="PYTHON"' API कॉल
अगले सेक्शन में, हम दोनों Python स्क्रिप्ट को इंटरैक्टिव स्पार्क जॉब, इलम की क्षमताओं का पूरा लाभ उठाते हुए।
चरण 2: इंटरएक्टिव मोड में संक्रमण
इंटरएक्टिव मोड एक रोमांचक विशेषता है जो स्पार्क विकास को अधिक गतिशील बनाती है, जिससे आपको वास्तविक समय में अपनी स्पार्क नौकरियों को चलाने, बातचीत करने और नियंत्रित करने की क्षमता मिलती है। यह उन लोगों के लिए डिज़ाइन किया गया है जो अपने स्पार्क अनुप्रयोगों पर अधिक प्रत्यक्ष नियंत्रण चाहते हैं।
इंटरएक्टिव मोड को अपने स्पार्क जॉब के साथ सीधी बातचीत के रूप में सोचें। आप डेटा में फ़ीड कर सकते हैं, परिवर्तनों का अनुरोध कर सकते हैं, और परिणाम प्राप्त कर सकते हैं - सभी वास्तविक समय में। यह आपकी डेटा प्रोसेसिंग पाइपलाइन की चपलता और क्षमता को काफी बढ़ाता है, जिससे यह बदलती आवश्यकताओं के लिए अधिक अनुकूलनीय और उत्तरदायी हो जाता है।
अब जब हम पायथन में एक बुनियादी स्पार्क जॉब बनाने से परिचित हैं, तो आइए अपनी नौकरी को एक इंटरैक्टिव में बदलकर चीजों को एक कदम आगे बढ़ाएं जो इलम की वास्तविक समय की क्षमताओं का लाभ उठा सकता है।
2.1 स्पार्कपाई उदाहरण।
यह बताने के लिए कि हमारी नौकरी को इंटरएक्टिव मोड में कैसे परिवर्तित किया जाए, हम अपने पहले को समायोजित करेंगे ilum_python_simple.py लिपि।
यादृच्छिक आयात यादृच्छिक से
ऑपरेटर आयात ऐड से
ilum.api import IlumJob से
क्लास SparkPiInteractiveExample(IlumJob):
डीईएफ रन (स्वयं, स्पार्क, कॉन्फ़िगरेशन):
विभाजन = int (config.get('विभाजन', '5'))
n = 100000 * विभाजन
def f(_: int) -> फ्लोट:
x = यादृच्छिक () * 2 - 1
y = यादृच्छिक () * 2 - 1
रिटर्न 1 अगर एक्स ** 2 + वाई ** 2 <= 1 और 0
गिनती = spark.sparkContext.parallelize (रेंज (1, एन + 1), विभाजन).मैप (एफ) .कम करें (जोड़ें)
वापसी "पाई लगभग % f"% (4.0 * गिनती / इसे इस रूप में सहेजें ilum_python_simple_interactive.py
मूल स्पार्कपी से कुछ ही अंतर हैं।
1. इलम पैकेज
शुरू करने के लिए, हम इलम जॉब इलम पैकेज से वर्ग, जो हमारे इंटरैक्टिव नौकरी के लिए बेस क्लास के रूप में कार्य करता है।
स्पार्क जॉब लॉजिक को एक ऐसे वर्ग में समझाया गया है जो फैली हुई है इलम जॉब , विशेष रूप से इसके भीतर चलाना विधि। हम इसके साथ इलम पैकेज जोड़ सकते हैं:
पाइप इलम स्थापित करें 2. एक कक्षा में स्पार्क नौकरी
स्पार्क जॉब लॉजिक को एक ऐसे वर्ग में समझाया गया है जो फैली हुई है इलम जॉब , विशेष रूप से इसके भीतर चलाना विधि।
क्लास SparkPiInteractiveExample(IlumJob):
डीईएफ रन (स्वयं, स्पार्क, कॉन्फ़िगरेशन):
# यहां जॉब लॉजिक नौकरी और उसके संसाधनों को संभालने के लिए इलम ढांचे के लिए एक कक्षा में नौकरी तर्क को लपेटना आवश्यक है। यह नौकरी को स्टेटलेस और पुन: प्रयोज्य भी बनाता है।
3. पैरामीटर अलग तरह से नियंत्रित किए जाते हैं:
हम config शब्दकोश से सभी तर्क ले रहे हैं
विभाजन = int (config.get('विभाजन', '5')) यह बदलाव अधिक गतिशील पैरामीटर पासिंग की अनुमति देता है और इलम के कॉन्फ़िगरेशन हैंडलिंग के साथ एकीकृत करता है।
4. परिणाम मुद्रित के बजाय लौटाया जाता है:
परिणाम से लौटाया जाता है चलाना विधि।
वापसी "पाई लगभग % f"% (4.0 * गिनती / परिणाम लौटाकर, इलम इसे अधिक लचीले तरीके से संभाल सकता है। उदाहरण के लिए, इलम परिणाम को क्रमबद्ध कर सकता है और इसे एपीआई कॉल के माध्यम से सुलभ बना सकता है।
5. स्पार्क सत्र को मैन्युअल रूप से प्रबंधित करने की आवश्यकता नहीं है
इलम हमारे लिए स्पार्क सत्र का प्रबंधन करता है। यह स्वचालित रूप से में इंजेक्ट किया जाता है चलाना मेथड और हमें इसे मैन्युअल रूप से रोकने की आवश्यकता नहीं है।
डीईएफ रन (स्वयं, स्पार्क, कॉन्फ़िगरेशन): ये परिवर्तन एक स्टैंडअलोन स्पार्क नौकरी से एक इंटरैक्टिव इलम नौकरी में संक्रमण को उजागर करते हैं। लक्ष्य नौकरी के लचीलेपन और पुन: प्रयोज्यता में सुधार करना है, जिससे यह गतिशील, इंटरैक्टिव और ऑन-द-फ्लाई संगणनाओं के लिए अधिक अनुकूल हो जाता है।
इंटरैक्टिव स्पार्क जॉब जोड़ना 'नए समूह' फ़ंक्शन के साथ संभाला जाता है।
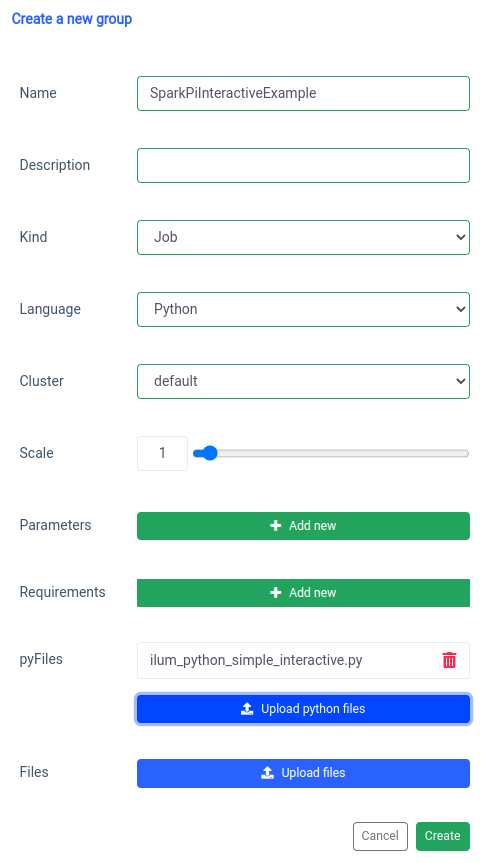
और यूआई पर इंटरैक्टिव जॉब फ़ंक्शन के साथ निष्पादन।
वर्ग का नाम एक के रूप में निर्दिष्ट किया जाना चाहिए pythonFileName.PythonClassImplementingIlumJob
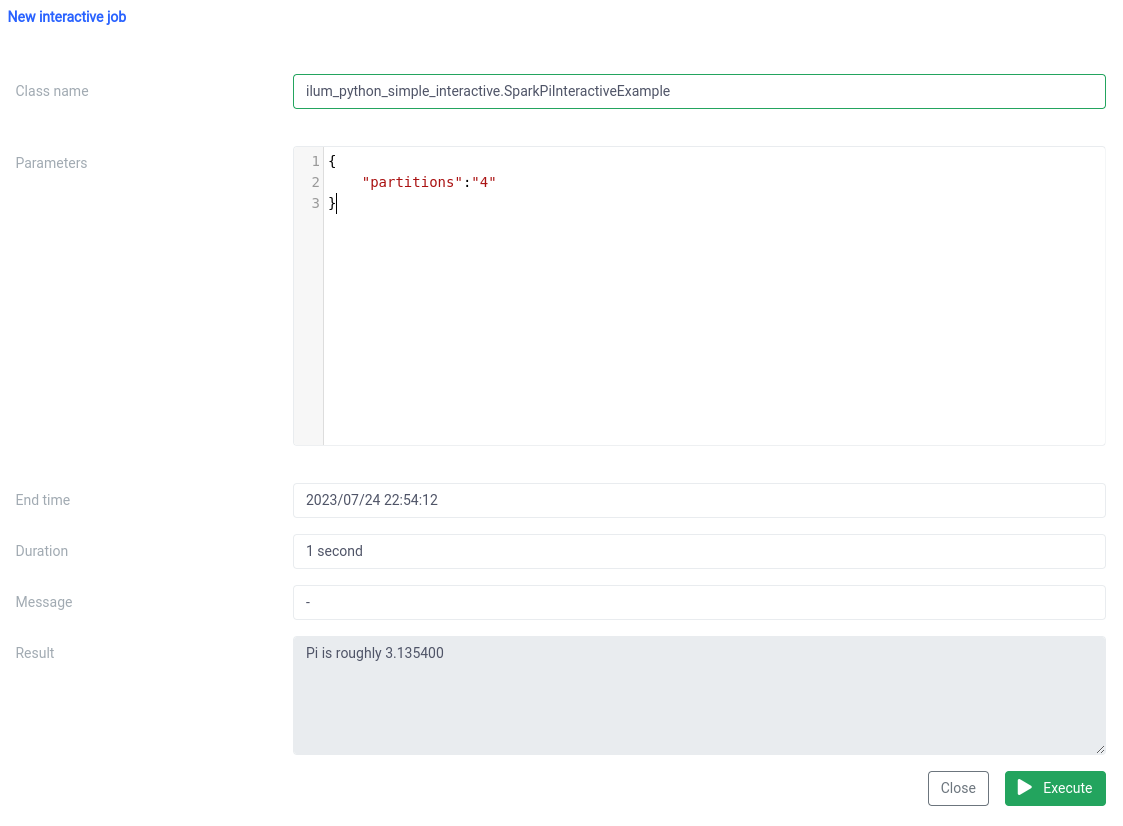
हम एक ही चीज़ के साथ हासिल कर सकते हैं एपीआई .
1. समूह बनाना
कर्ल -एक्स पोस्ट 'लोकलहोस्ट: 9888/एपीआई/वी1/ग्रुप' \
--फॉर्म 'नाम = "SparkPiInteractiveExample"' \
--फॉर्म 'तरह = "नौकरी"' \
--फॉर्म 'क्लस्टरनाम = "डिफ़ॉल्ट"' \
--फॉर्म 'pyFiles=@"/path/to/ilum_python_simple_interactive.py"' \
--form 'language="PYTHON"' API कॉल
{"groupId":"20230726-1638-mjrw3"} परिणाम
2. नौकरी निष्पादन
कर्ल -एक्स पोस्ट 'लोकलहोस्ट: 9888/एपीआई/वी1/ग्रुप/20230726-1638-एमजेआरडब्ल्यू3/जॉब/एक्जीक्यूट' \
-एच 'सामग्री-प्रकार: आवेदन/जेसन' \
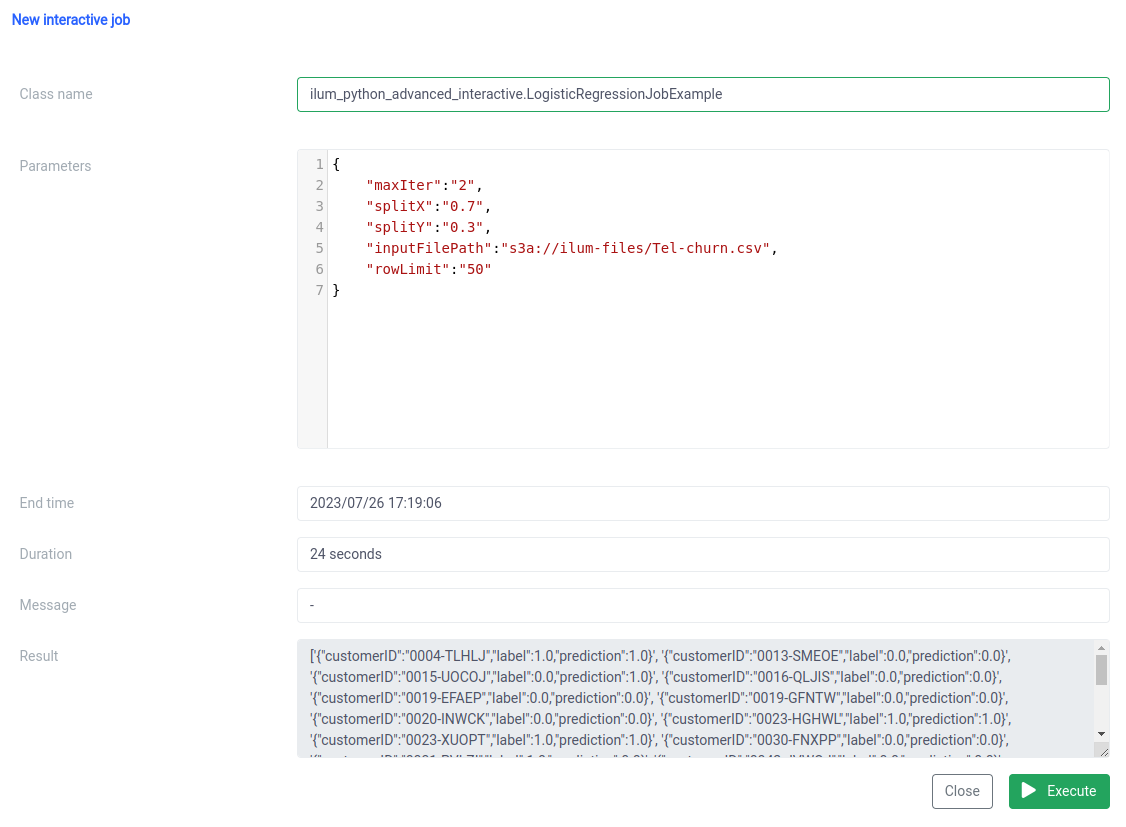
-d '{ "jobClass":"ilum_python_simple_interactive। SparkPiInteractiveExample", "jobConfig": {"विभाजन":"10"}, "प्रकार":"interactive_job_execute"}' API कॉल
{
"jobInstanceId":"20230726-1638-mjrw3-a1srahhu",
"जॉब आईडी":"20230726-1638-mjrw3-wwt5a",
"ग्रुपआईडी":"20230726-1638-mjrw3",
"स्टार्टटाइम":1690390323154,
"समाप्ति समय":1690390325200,
"जॉबक्लास":"ilum_python_simple_interactive। SparkPiInteractiveExample",
"jobConfig":{
"विभाजन":"10"
},
"परिणाम": "पाई लगभग 3.149400 है",
"त्रुटि": शून्य
} परिणाम
2.2 सुन्न के साथ नौकरी का उदाहरण।
आइए हमारे दूसरे उदाहरण को देखें।
pyspark.sql आयात से SparkSession
pyspark.ml आयात पाइपलाइन से
pyspark.ml.feature से आयात स्ट्रिंगइंडेक्सर, वेक्टरअसेंबलर
pyspark.ml.classification से आयात LogisticRegression
ilum.api import IlumJob से
क्लास लॉजिस्टिकरिग्रेशनजॉबउदाहरण (इलम जॉब):
def run (स्वयं, spark_session: SparkSession, config: dict) -> str:
df = spark_session.read.csv(config.get('inputFilePath', 's3a://ilum-files/Tel-churn.csv'), header=True,
inferSchema=True)
श्रेणीबद्ध कॉलम = ['लिंग', 'साथी', 'आश्रित', 'फोन सेवा', 'मल्टीपललाइन्स', 'इंटरनेट सेवा',
'ऑनलाइन सुरक्षा', 'ऑनलाइन बैकअप', 'डिवाइस प्रोटेक्शन', 'टेकसपोर्ट', 'स्ट्रीमिंगटीवी',
'स्ट्रीमिंगमूवीज', 'कॉन्ट्रैक्ट', 'पेपरलेस बिलिंग', 'पेमेंट मेथड']
चरण = []
categoricalColumns में categoricalCol के लिए:
stringIndexer = StringIndexer (inputCol = categoricalCol, outputCol = categoricalCol + "इंडेक्स")
चरण + = [स्ट्रिंगइंडेक्सर]
label_stringIdx = स्ट्रिंगइंडेक्सर (इनपुटकोल = "मंथन", आउटपुटकोल = "लेबल")
चरण += [label_stringIdx]
संख्यात्मक Cols = ['वरिष्ठ नागरिक', 'कार्यकाल', 'मासिक शुल्क']
assemblerInputs = [c + "सूचकांक" categoricalColumns में c के लिए] + संख्यात्मक Cols
कोडांतरक = वेक्टरअसेंबलर (इनपुटकोल्स = असेंबलरइनपुट, आउटपुटकोल = "फीचर्स")
चरण += [कोडांतरक]
पाइपलाइन = पाइपलाइन (चरण = चरण)
pipelineModel = pipeline.fit(df)
डीएफ = pipelineModel.transform(df)
ट्रेन, परीक्षण = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))],
बीज = इंट (कॉन्फ़िगरेशन.गेट ('बीज', '42')))
lr = LogisticRegression (featuresCol = "features", labelCol = "label", maxIter = int (config.get('maxIter', '5')))
lrModel = lr.fit (ट्रेन)
भविष्यवाणियां = lrModel.transform (परीक्षण)
वापसी '{}'.format(predictions.select("customerID", "लेबल", "भविष्यवाणी").limit(
int(config.get('rowLimit', '5'))).toJSON().collect()) 1. हम पिछले उदाहरण की तरह ही एक कक्षा में नौकरी लपेटते हैं:
क्लास लॉजिस्टिकरिग्रेशनजॉबउदाहरण (इलम जॉब):
def run (स्वयं, spark_session: SparkSession, config: dict) -> str:
# यहां जॉब लॉजिक फिर से, नौकरी तर्क में समझाया गया है चलाना एक वर्ग विस्तार की विधि इलम जॉब , इलम को कुशलता से काम संभालने में मदद करता है।
2. डेटा पाइपलाइन (जैसे फ़ाइल पथ और लॉजिस्टिक रिग्रेशन हाइपरपैरामीटर) के लिए उन सभी मापदंडों सहित, से प्राप्त किए जाते हैं कॉन्फिग विश्वकोशीय शब्दकोश:
df = spark_session.read.csv(config.get('inputFilePath', 's3a://ilum-files/Tel-churn.csv'), header=True, inferSchema=True)
ट्रेन, परीक्षण = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))], seed=int(config.get('बीज', '42')))
lr = LogisticRegression (featuresCol = "features", labelCol = "label", maxIter = int (config.get('maxIter', '5'))) सभी मापदंडों को एक ही स्थान पर केंद्रीकृत करके, इलम नौकरी को कॉन्फ़िगर करने और ट्यून करने का एक समान, सुसंगत तरीका प्रदान करता है।
किसी विशिष्ट स्थान पर लिखे जाने के बजाय नौकरी का परिणाम JSON स्ट्रिंग के रूप में लौटाया जाता है:
वापसी '{}'.format(predictions.select("customerID", "लेबल", "भविष्यवाणी").limit(int(config.get('rowLimit', '5')))).toJSON().collect()) यह नौकरी के परिणाम के अधिक गतिशील और लचीले संचालन की अनुमति देता है, जिसे तब आवेदन की जरूरतों के आधार पर एपीआई के माध्यम से आगे संसाधित या उजागर किया जा सकता है।
यह कोड पूरी तरह से दिखाता है कि कैसे हम इंटरैक्टिव, एपीआई-संचालित डेटा प्रोसेसिंग पाइपलाइनों को सक्षम करने के लिए इलम के साथ PySpark नौकरियों को मूल रूप से एकीकृत कर सकते हैं। पाई सन्निकटन जैसे सरल उदाहरणों से लेकर लॉजिस्टिक रिग्रेशन जैसे अधिक जटिल मामलों तक, इलम की इंटरैक्टिव नौकरियां बहुमुखी, अनुकूलनीय और कुशल हैं।
चरण 3: अपने स्पार्क जॉब को एक माइक्रोसर्विस बनाना
माइक्रोसर्विसेज पारंपरिक अखंड अनुप्रयोग संरचना से अधिक मॉड्यूलर और चुस्त दृष्टिकोण में एक प्रतिमान बदलाव लाते हैं। एक जटिल एप्लिकेशन को छोटी, शिथिल युग्मित सेवाओं में तोड़कर, विशिष्ट आवश्यकताओं के आधार पर प्रत्येक सेवा को स्वतंत्र रूप से बनाना, बनाए रखना और स्केल करना आसान हो जाता है। जब हमारे स्पार्क नौकरी पर लागू किया जाता है, तो इसका मतलब है कि हम एक मजबूत डेटा प्रोसेसिंग सेवा बना सकते हैं जिसे हमारे एप्लिकेशन स्टैक के अन्य हिस्सों को प्रभावित किए बिना स्केल, प्रबंधित और अपडेट किया जा सकता है।
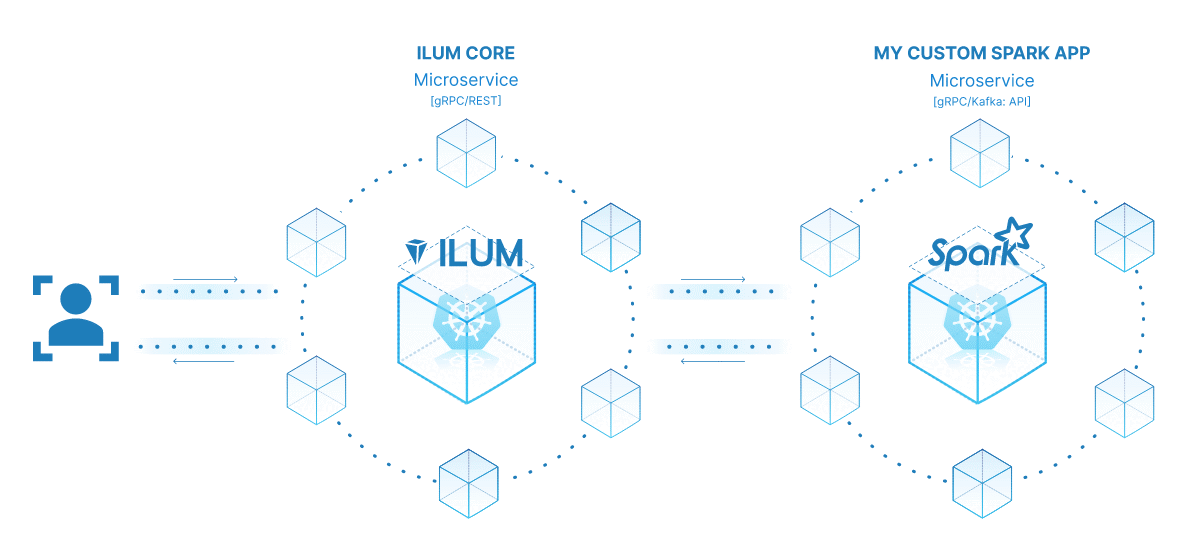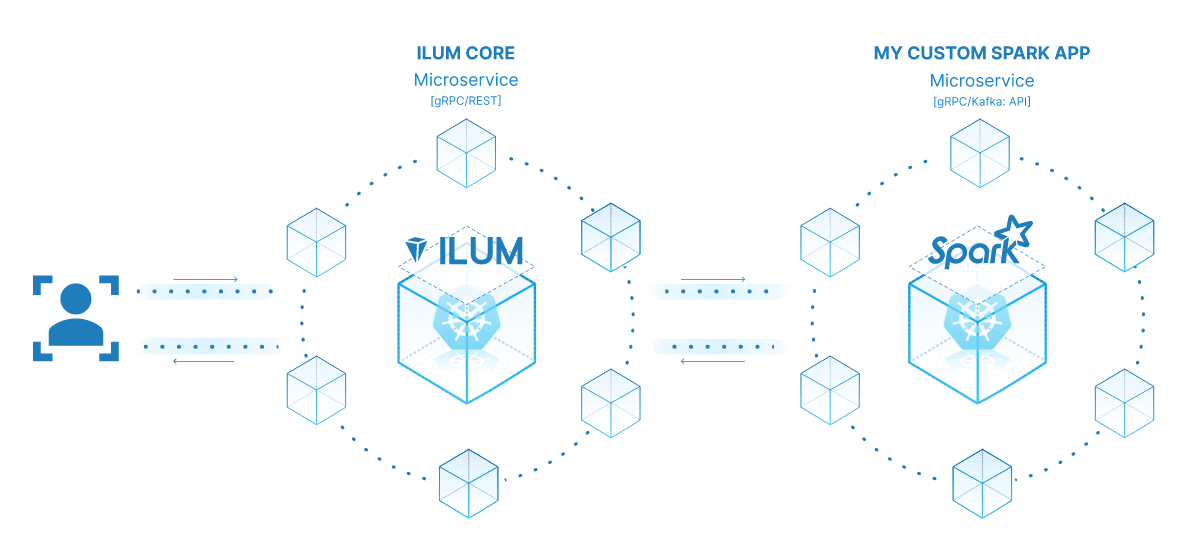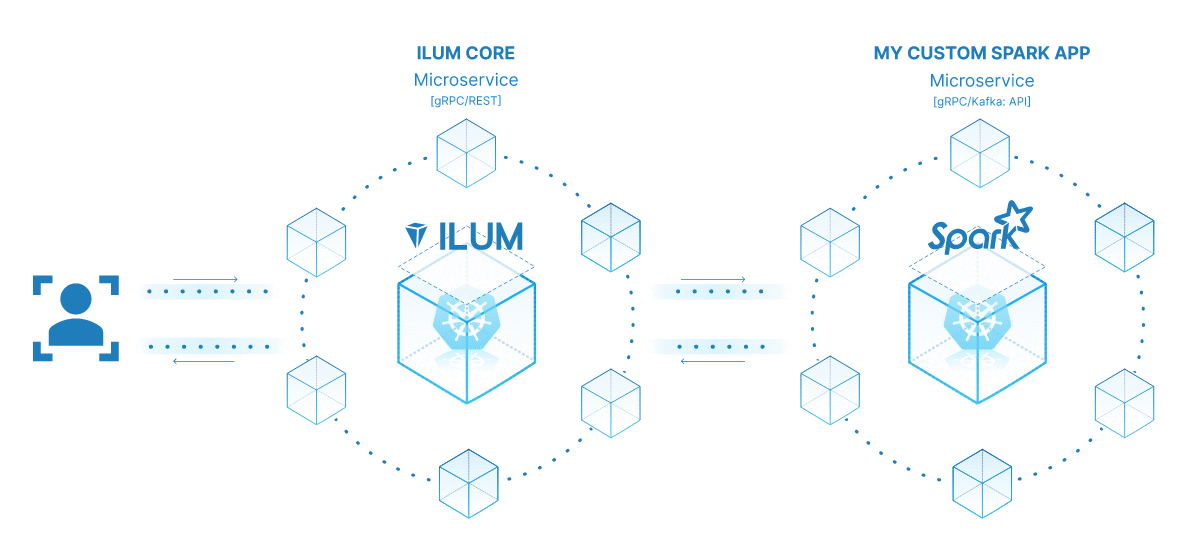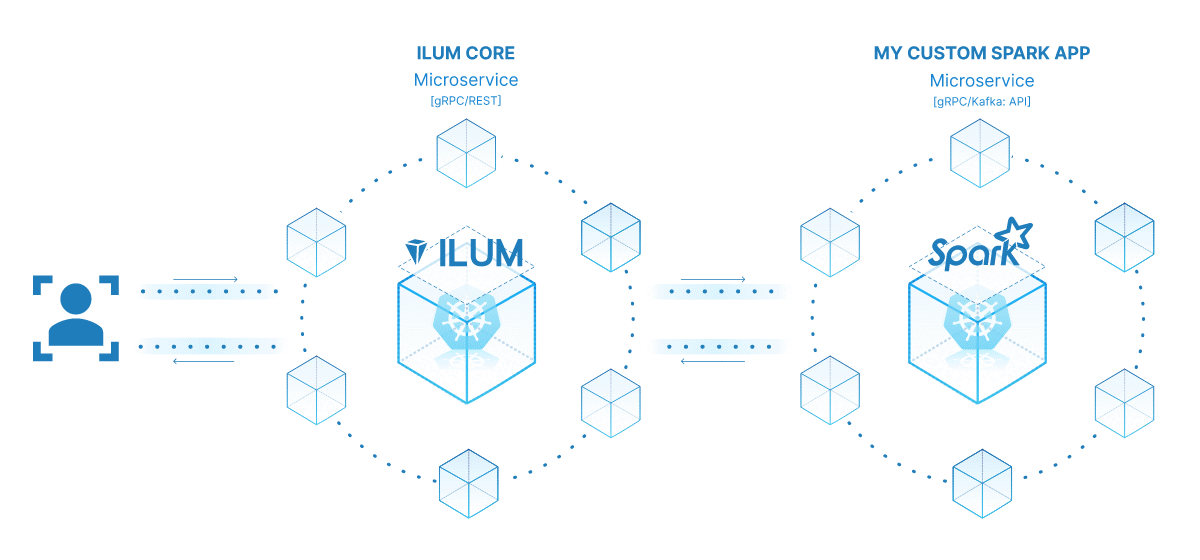
अपने स्पार्क जॉब को माइक्रोसर्विस में बदलने की शक्ति इसकी बहुमुखी प्रतिभा, मापनीयता और रीयल-टाइम इंटरैक्शन क्षमताओं में निहित है। एक माइक्रोसर्विस एक एप्लिकेशन का एक स्वतंत्र रूप से तैनाती योग्य घटक है जो एक अलग प्रक्रिया के रूप में चलता है। यह अच्छी तरह से परिभाषित एपीआई के माध्यम से अन्य घटकों के साथ संचार करता है, जिससे आपको प्रत्येक माइक्रोसर्विस को स्वतंत्र रूप से डिजाइन, विकसित, तैनात और स्केल करने की स्वतंत्रता मिलती है।
इलम के संदर्भ में, एक इंटरैक्टिव स्पार्क नौकरी को माइक्रोसर्विस के रूप में माना जा सकता है। नौकरी की 'रन' विधि एपीआई समापन बिंदु के रूप में कार्य करती है। हर बार जब आप इलम के एपीआई के माध्यम से इस विधि को कॉल करते हैं, तो आप इस माइक्रोसर्विस के लिए अनुरोध कर रहे हैं। यह आपके स्पार्क नौकरी के साथ वास्तविक समय की बातचीत की संभावना को खोलता है।
आप विभिन्न अनुप्रयोगों या स्क्रिप्ट से अपने माइक्रोसर्विस के लिए अनुरोध कर सकते हैं, डेटा प्राप्त कर सकते हैं, और मक्खी पर परिणाम संसाधित कर सकते हैं। इसके अलावा, यह आपके डेटा प्रोसेसिंग पाइपलाइनों के आसपास अधिक जटिल, सेवा-उन्मुख आर्किटेक्चर बनाने का अवसर खोलता है।
इस सेटअप का एक प्रमुख लाभ मापनीयता है। Ilum UI या API के माध्यम से, आप लोड या कम्प्यूटेशनल जटिलता के आधार पर अपनी नौकरी (माइक्रोसर्विस) को ऊपर या नीचे स्केल कर सकते हैं। आपको संसाधनों को मैन्युअल रूप से प्रबंधित करने या लोड संतुलन के बारे में चिंता करने की आवश्यकता नहीं है। इलम का आंतरिक लोड बैलेंसर आपके स्पार्क जॉब के उदाहरणों के बीच एपीआई कॉल वितरित करेगा, जिससे कुशल संसाधन उपयोग सुनिश्चित होगा।
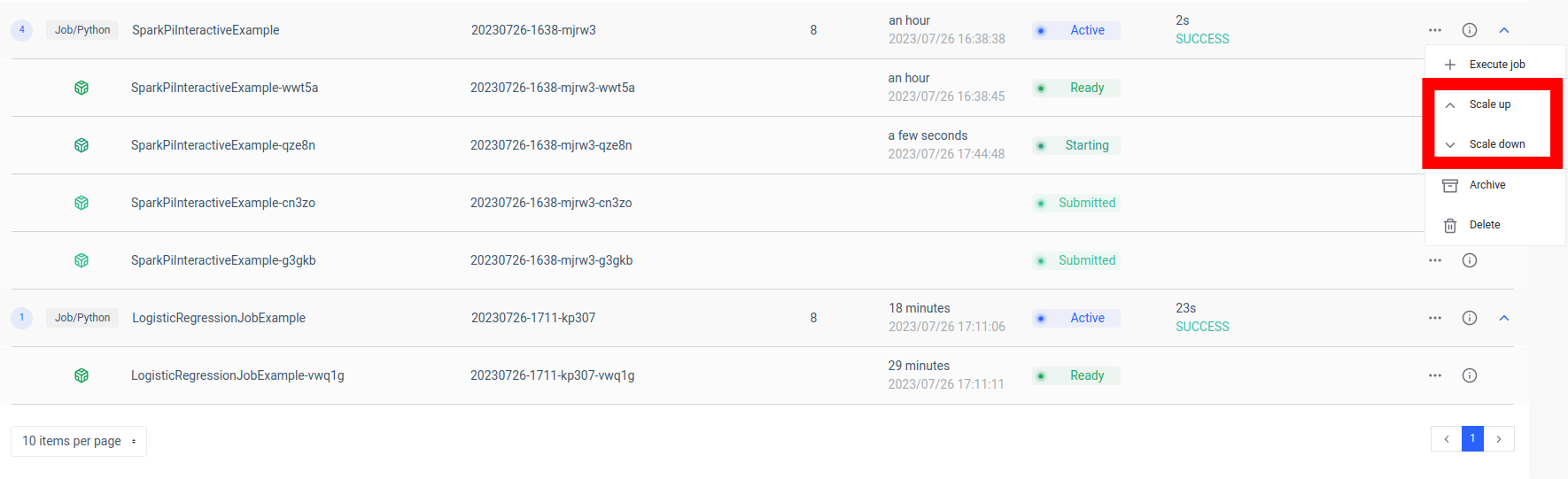
ध्यान रखें कि नौकरी का वास्तविक प्रसंस्करण समय स्पार्क नौकरी की जटिलता और इसके लिए आवंटित संसाधनों पर निर्भर करता है। हालाँकि, कुबेरनेट्स द्वारा प्रदान की गई मापनीयता के साथ, आप अपनी नौकरी की आवश्यकताओं के बढ़ने पर अपने संसाधनों को आसानी से बढ़ा सकते हैं।
इलम, अपाचे स्पार्क और माइक्रोसर्विसेज का यह संयोजन आपके डेटा को संसाधित करने के लिए एक नया, चुस्त तरीका लाता है - कुशलतापूर्वक, स्केलेबल और उत्तरदायी रूप से!

डेटा माइक्रोसर्विस आर्किटेक्चर में गेम-चेंजर
हम एक लंबा सफर तय कर चुके हैं क्योंकि हमने इलम का उपयोग करके एक साधारण पायथन अपाचे स्पार्क नौकरी को एक पूर्ण विकसित माइक्रोसर्विस में बदलने की इस यात्रा को शुरू किया है। हमने देखा कि स्पार्क जॉब लिखना कितना आसान था, इसे इंटरेक्टिव मोड में काम करने के लिए अनुकूलित करें, और अंततः इसे इलम के मजबूत एपीआई की मदद से माइक्रोसर्विस के रूप में उजागर करें। रास्ते में, हमने पायथन की शक्ति, अपाचे स्पार्क की क्षमताओं और इलम के लचीलेपन और मापनीयता का लाभ उठाया। इस संयोजन ने न केवल हमारी डेटा प्रोसेसिंग क्षमताओं को बदल दिया है बल्कि डेटा आर्किटेक्चर के बारे में हमारे सोचने के तरीके को भी बदल दिया है।
यात्रा यहीं नहीं रुकती। इलम पर पूर्ण पायथन समर्थन के साथ, डेटा प्रोसेसिंग और एनालिटिक्स के लिए संभावनाओं की एक नई दुनिया खुलती है। जैसा कि हम इलम पर निर्माण और सुधार करना जारी रखते हैं, हम भविष्य की संभावनाओं के बारे में उत्साहित हैं जो पायथन हमारे मंच पर लाता है। हम मानते हैं कि पायथन और इलम के साथ, हम डेटा माइक्रोसर्विस आर्किटेक्चर की दुनिया में क्या संभव है, इसे फिर से परिभाषित करने की शुरुआत में हैं।
इस रोमांचक यात्रा में हमसे जुड़ें, और आइए एक साथ डेटा प्रोसेसिंग के भविष्य को आकार दें!